 Usted puede o no ser consciente de que hay un debate en curso acerca del modo "cierto" de implementar comuncación heterogénea entre
Usted puede o no ser consciente de que hay un debate en curso acerca del modo "cierto" de implementar comuncación heterogénea entre
aplicaciones: Si bien la actual corriente principal se centra claramente en los servicios web basados en SOAP, WSDL y el universo de las especificaciones WS-* , una pequeña, pero significativa minoría sostiene que hay una mejor manera: REST, abreviación de "REpresentational State Transfer". En este artículo, trataremos dar una introducción práctica a REST y la integración de aplicaciones HTTP RESTful sin entrar en este debate.
Principios fundamentales de REST
La mayoría de las introducciones de REST comienzan con una definición formal y su historia. Voy a escapar de eso por un momento y daré una simple y pragmática definición: REST es un conjunto de principios que definen cómo Estándares Web como HTTP, URI deben utilizarse (lo que a menudo difiere un poco de lo que muchas personas actualmente hacen). La promesa es que si se adhieren a los principios REST mientras esté diseñando la aplicación, tendrá un sistema que opera la arquitectura Web para su beneficio. En resumen, los cinco principios son los siguientes:
- Dar a todas las cosas un identificador
- Vincular las cosas
- Use métodos estándar
- Recursos con múltiples representaciones
- Comunique sin estado
Echemos un vistazo más de cerca cada uno de estos principios.
Dar a todas las "cosas" un ID
Estoy usando la palabra "cosas" en lugar del termino formalmente correcto "recurso" porque se trata de un simple principio de que no debe estar oculto detrás de la terminología. Si usted piensa acerca de los sistemas que las personas construyen suele haber un
conjunto de abstracciones clave que merecen ser identificadas. Todo lo que debe ser identificado, por supuesto, debe tener un ID - En la Web, hay un concepto unificado para los números de identificación: La URI. URI comprende un espacio de nombres global, y utilizando URI's para identificar sus recursos clave significa tener un ID único y global.
El principal beneficio de un esquema de nombres para las cosas es que usted no tiene que crear su propio sistema - puede confiar en una ya definida, que funciona muy bien en una escala global y es entendido prácticamente por cualquiera. Si considera un objeto arbitrario de alto nivel con la última aplicación que construyó (suponiendo que no se construyó de forma RESTful), es casi seguro que había muchos casos de uso donde debería haberse beneficiado de eso. Si su aplicación contiene una abstracción de Cliente, por ejemplo, estoy casi seguro de que los usuarios gustarían de poder enviar un vínculo para un determinado cliente a través de e-mail, para un colega en el trabajo, para crear un marcador para él en su navegador, o incluso escribirlo sobre una hoja de papel. Para aclarar mejor, imagine que una decisión de negocios terriblemente mala hubiera sido si una tienda online como amazon.com no identificase cada uno de sus productos con una única ID (una URI).
Cuando se enfrentan con esta idea, muchas personas se preguntan si esto significa que deben exponer sus entradas de la base de datos
(o sus números de identificación) directamente - y, a menudo, se enojan por la simple idea, una vez que años de práctica de orientación a los objetos nos dicen que debemos ocultar los aspectos de las bases de datos. Por ejemplo, un recurso de Pedido podría estar compuesto de los temas de pedido, una dirección y muchos otros aspectos que usted podría no querría exponer como un recurso identificable individualmente. Tomando la idea de identificar de todo lo que vale la pena ser identificado, lleva a la creación de recursos que usted no suele ver, en un típico diseño de la aplicación: un proceso o un paso de un proceso, una venta, una negociación, un solicitud de cotización - estos son todos los ejemplos de "cosas" que necesitan ser identificadas. Esto, a su vez, puede conducir a la creación de entidades más persistentes que en un diseño no RESTful.
Algunos ejemplos ejemplos de URI que podría tener:
- http://example.com/customers/1234
- http://example.com/orders/2007/10/776654
- http://example.com/products/4554
- http://example.com/processes/salary-increase-234
Como yo escogí crear las URIs que puedan ser leídas por los seres humanos - un concepto útil, aunque no es un pre-requisito previo para un diseño RESTful - debería ser bastante fácil de adivinar su significado: identificar ellas obviamente identifican que "elementos" individuales. Pero eche sólo un vistazo a estos:
- http://example.com/orders/2007/11
- http://example.com/products?color=green
En primer lugar, esto puede parecer algo diferente - después de todo, no son la identificación de una cosa, pero una serie de cosas (suponiendo que la primera URI identifica todos los pedidos presentados en noviembre de 2007, y en segundo lugar, un conjunto de productos de color verde). Pero estos conjuntos son realmente cosas -recursos- por sí solos, y ellos definitivamente necesitan tener un identificador.
Tenga en cuenta los beneficios de tener un único esquema de nombres a nivel global aplicable tanto a la Web en su navegador como para la comunicación de máquina a máquina.
Para resumir el primer principio: Utilice URIs para identificar todo lo que necesita ser identificado, especifique todos los recursos de "alto nivel" que su aplicativo ofrece, en caso de que ellos represente elementos individuales, conjunto de elementos, objetos virtuales y físicos, o los resultados de computación.
Vincule las cosas
El siguiente principio que veremos tiene una descripción formal que intimida un poco: "hipermedia como motor de estado del aplicativo," a veces abreviado como HATEOAS. (Realmente - No estoy inventando esto.) En su centro se encuentra el concepto de hipermídia, o en otras palabras: vínculos (links). Los enlaces (links) son algo en lo que estamos familiarizados con HTML, pero que no son de ninguna manera limitados al consumo de los seres humanos. Considere el siguiente fragmento de XML:
<order self="http://example.com/customers/1234">
<amount>23</amount>
<product ref="http://example.com/products/4554"></product>
<customer ref="http://example.com/customers/1234"></customer>
</order>
Si se observa los links del producto (product) y del cliente (customer) en este documento, usted puede fácilmente imaginar cómo una aplicación que lo ha obtenido puede interpretar los vínculos (links) para obtener más información. Por supuesto, este sería el caso si hay un simple atributo identificador adherido a algún esquema de nomeclatura específica de una aplicación, también - pero sólo en el contexto del aplicativo. La belleza del enfoque de los vínculos con las URIs es que los enlaces (links) pueden apuntar a los recursos que son ofrecidos por una aplicación diferente, en otro servidor, o incluso en una empresa distinta en otro continente - porque el esquema de denominación es un estándar global, todos los recursos que hacen la Web pueden ser conectados el uno al otro.
Aún un aspecto mas importante del principio de hipermedia -la parte del estado del aplicativo. En resumen, el hecho de que el servidor (o proveedor de servicios, si lo prefiere) ofrece una colección de vínculos (links) para el cliente (el consumidor del servicio), permite al cliente cambiar el aplicativo de un estado a otro, a través de un vínculo (link). Vamos a observar los efectos de este aspecto en otro artículo, pronto, por ahora, tenga en mente que los vínculos (links) son extremadamente útiles para hacer una aplicación dinámica.
Para resumir estos principios: Utilice links para hacer referencia a cosas que puedan ser identificadas (los recursos) siempre que sea posible. Los hipervínculos son lo que hacen la Web lo que es la Web.
Utilice los métodos estándar
Había un supuesto implícito en la discusión de los dos primeros principios: la aplicación consumidor puede realmente hacer algo significativo con URIs. Si usted ve una URI escrita en el lateral de un autobús, usted puede ponerla en la barra de direcciones de su navegador y pulsar ENTER - pero como es que su navegador sabe qué hacer con el URI?
Él sabe qué hacer con ella, porque todos los recursos tienen la misma interfaz y el mismo conjunto de métodos (u operaciones, si usted prefiere). HTTP los llama verbos, y además de los dos que todo el mundo conocee (GET y POST), el conjunto de métodos normalizados
incluyen, PUT, DELETE, HEAD y OPTIONS. El significado de cada uno de estos métodos está definido en la especificación HTTP, junto con algunas garantías acerca de su comportamiento. Si usted es un desarrollador OO, se puede imaginar que todos los recursos en un escenario HTTP RESTful extienden una clase como ésta (en alguna pseudo-sintaxis en estilo Java/C# concentradonos en los principales métodos):
class Resource {
Resource(URI u);
Response get();
Response post(Request r);
Response put(Request r);
Response delete();
}
Debido al hecho que la misma interfaz se utiliza para todos los recursos, puede confiar que es posible obtener una representación -o sea, una prestación (rederización) del recurso- utilizando GET. Como la semántica de GET se define en la especificación, usted puede estar seguro de que tiene obligaciones cuando lo llaman -es por ello que el método se llama "seguro". GET soporta caché de forma muy eficiente y sofisticada, en muchos casos, ni siquiera necesita enviar una petición al servidor. También puede asegurarse de que GET es idempotente - si envía una solicitud GET y no obtiene un resultado, usted no puede saber si su solicitud nunca llegó a su destino o si la respuesta se perdió en el camino de regreso. La seguridad de idempotência significa que usted puede simplemente que puede enviar la solicitud de nuevo. El idempotência también está garantizada para PUT (que básicamente significa "actualizar el recurso sobre la base de estos datos, o crear en la URI si no está ya allí") y para DELETE (que usted puede simplemente intentar una y otra vez hasta obtener un resultado - borrar algo que no existe no es un problema). POST, que por lo general significa "crear un nuevo recurso," también se puede utilizar para invocar un proceso arbitrario, por lo tanto, no es ni segura ni Idempotente.
Si usted expone las funcionalidad de su aplicación (o funcionalidades del servicio, si lo prefiere) de modo RESTful, ese principio y sus restricciones se aplican a usted también. Es difícil de aceptar si está familiarizado con un enfoque diferente para el diseño - después de todo, usted está probablemente convencido de que su aplicación tiene mucha más lógica de lo que se expresa en operaciones manuales. Permítame pasar algún tiempo tratando de convencerlo de que ese no es el caso.
Considere el siguiente ejemplo de un simple escenario de compras:
Usted puede ver que hay dos servicios que se definen aquí (sin que ello implique ninguna implementación tecnologica específica). La interfaz de estos servicios es específica para la tarea - son los servicios OrderManagement (Administrador de Pedidos) y CustomerManagement (Administrador de Clietnes) de los que estamos hablando. Si un cliente (aplicación) desea consumir este servicio, es necesario codificar sobre esa interfaz específica - no hay manera de utilizar un cliente que se construyó antes de que estas interfaces se han especificado para interactuar con ellas. Las interfaces definen el protocolo de los servicios del aplicativo.
En un abordaje HTTP RESTful, usted tendría que comenzar con un interfaz genérica que compone el protocolo HTTP de la aplicación. Usted
podría hacer algo como esto: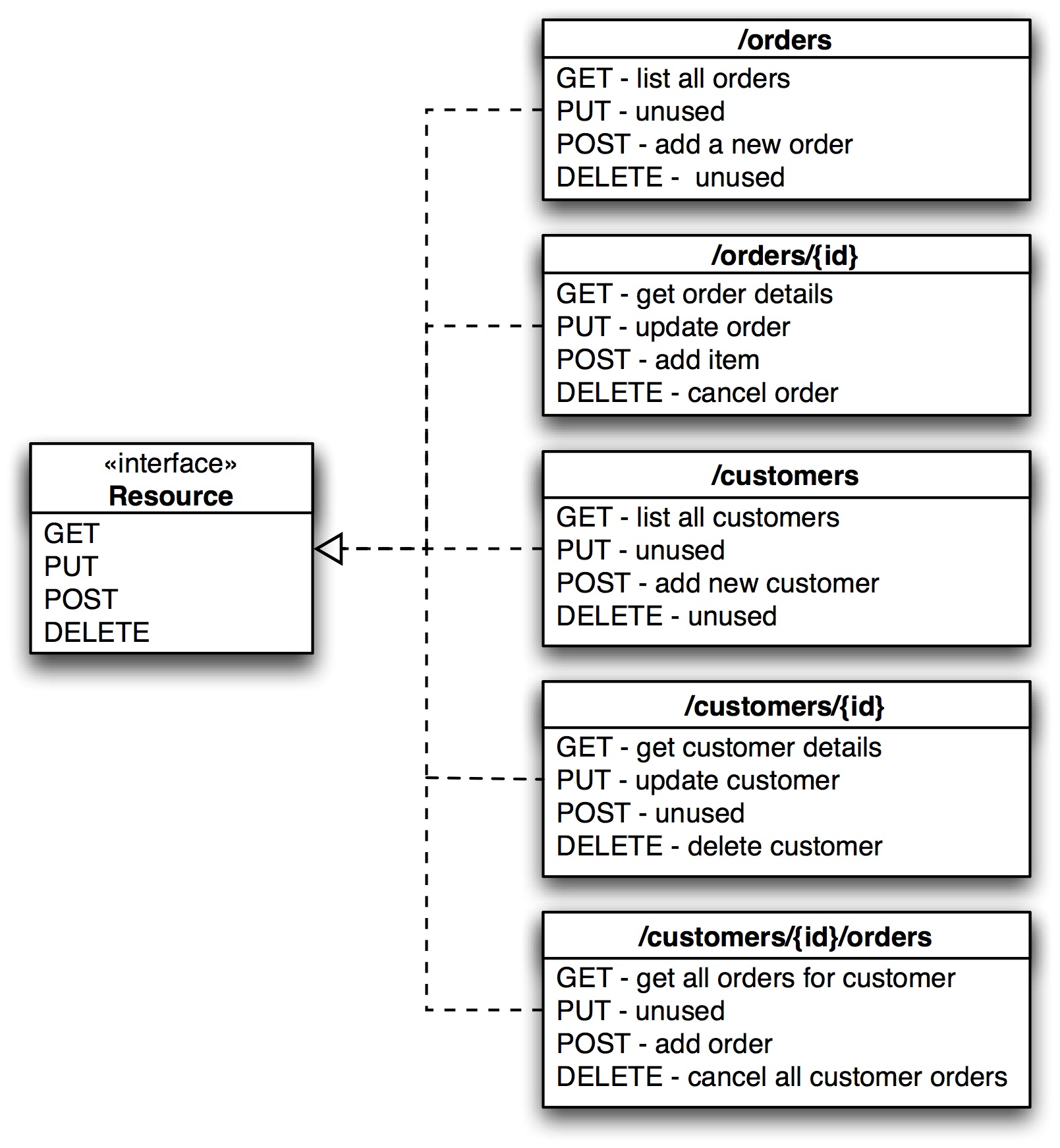
Usted puede ver que lo que tiene operaciones específicas de un servicio que fue mapeado a los métodos estándar de HTTP - y para diferenciar. He creado un universo entero de nuevos recursos. "Eso es trampa!", Oigo como usted llora. No - no lo es. Un GET en una URI que identifica a un cliente es tan importante como una operación getCustomerDetails. Algunas personas usan un triángulo para ver esto: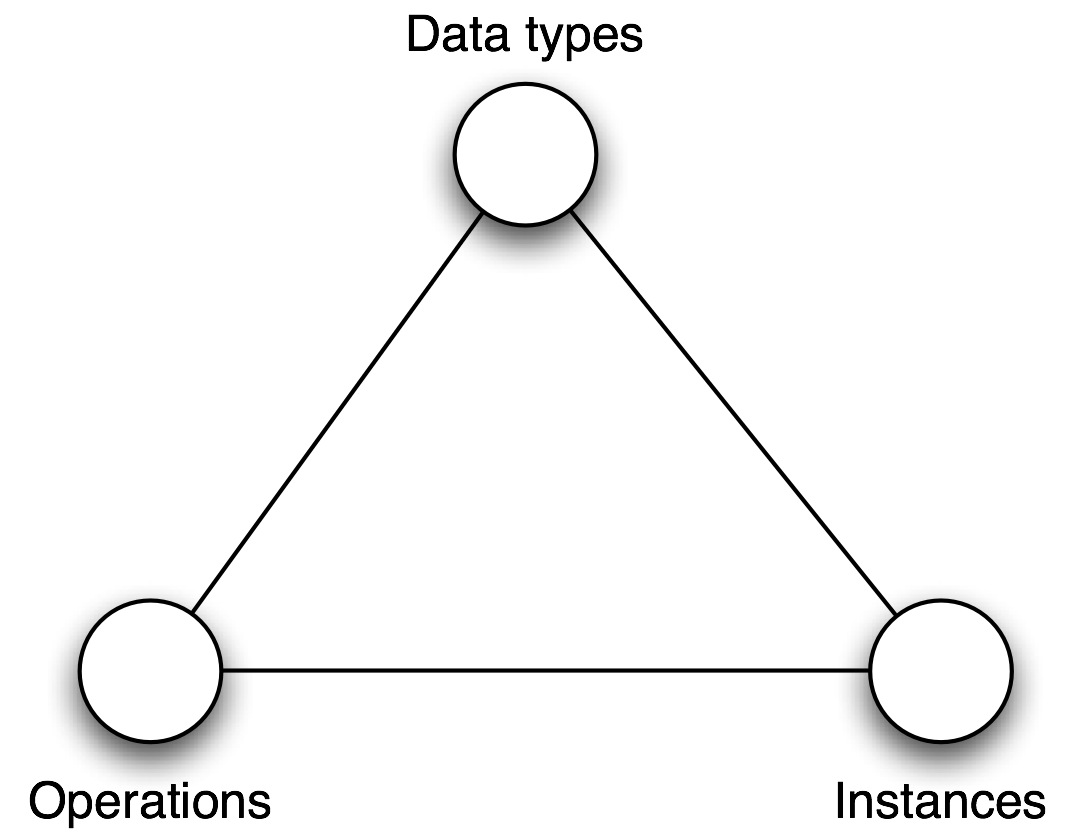
Imagine los tres vértices como algo que ested puede girar. Usted puede ver que en el primer enfoque, usted tiene muchas operaciones y muchos tipos de datos y un número determinado de "instancias" (esencialmente, tantas cómo servicios tenga). El segundo enfoque, tiene
un número determinado de operaciones, muchos tipos de datos y muchos objetos para invocar este método en particular. El punto es
demostrar que puede básicamente expresar cualquier cosa que quiera desde ambos enfoques.
Porque es importante esto? En esencia, hace que su aplicación sea parte de la Web -su contribución para lo que se convirtió la Web, la aplicación de más éxito de Internet es proporcional al número de recursos que su aplicación añada a ella. En un enfoque RESTfull, una aplicación puede añadir algunos millones de URI's de clientes en la Web; Si fuera concebida de la misma manera que los aplicactivos de los días de CORBA, esta contribución es a menudo un único "endpoint" - comprando una puerta muy pequeña que ofrece la entrada a un universo de recursos sólo para aquellos que tienen la clave.
La interfaz uniforme también permite que cualquier componente que comprende el protocolo de aplicación HTTP interactúa con su aplicación. Ejemplos de componentes que son beneficiados por eso son clientes genéricoscomo curl, o wget, proxies, cachés, servidores HTTP, gateways e incluso Google, Yahoo, MSN y muchos otros.
Para resumir: Para que los clientes puedan interactúan con sus recursos, ellos deberían implementar el protocolo de aplicación estandard (HTTP) correctamente, es decir, utilizando los métodos estándar: GET, PUT, POST y DELETE.
Recursos con múltiples representaciones
Ignoramos una ligera complicación hasta ahora: ¿Cómo es qué un cliente sabe cómo manejar los datos que obtiene, por ejemplo, como resultado de un GET o POST? El enfoque de HTTP permite una separación entre las responsabilidades de manejo de datos y la invocación de operaciones. En otras palabras, un cliente que sabe cómo hacer frente a un formato específico de datos pueden interactuar con todos los recursos que puede ofrecer una representación en ese formato. Vamos a ilustrar esto de nuevo, con un ejemplo. Utilizando la negociación de contenido HTTP, un cliente puede pedir una representación en un formato específico:
GET /customers/1234 HTTP/1.1
Host: example.com
Accept: application/vnd.mycompany.customer+xml
El resultado puede ser un XML en algun formato específico de una empresa que representa los datos de un cliente. Si el cliente (HTTP) envía una solicitud diferente, es decir, como esta:
GET /customers/1234 HTTP/1.1
Host: example.com
Accept: text/x-vcard
El resultado podría ser la dirección de un cliente en formato vCard. (No estoy mostrando las respuestas, que incluirían metadatos sobre el tipo de dato en el encabezado del tipo de contenido HTTP.) Esto ilustra por qué, idealmente, las representaciones de un recurso deben ser en formato estándar -si un cliente "conoce" ambos, los protocolos HTTP y un conjunto de formato de datos, puede interactuar con cualquier aplicación HTTP RESTful del mundo de forma muy significativa. Lamentablemente, no tenemos formatos normalizados para todo, pero probablemente pueda imaginar cómo podría crear un ecosistema menor en una empresa o en un conjunto de los trabajadores sobre la base de formatos estándar. Seguramente todo esto no es sólo para los datos enviados desde un servidor a un cliente, sino también en la dirección opuesta - un servidor que puede consumir datos en un formato específico no se preocupa por el tipo específico de cliente, siempre que cumpla con el protocolo de aplicación.
Hay otro importante beneficio de contar con múltiples formatos de un recurso en la práctica: Si usted proporciona tanto un HTML y un formato XML de sus recursos, ellos pueden ser consumidos no sólo por su aplicación, sino por cualquier navegador Web estándar -en otras palabras, la información de su aplicación estará a disposición de cualquiera que sepa cómo utilizar la Web.
Hay otra manera de explorar esto: puede cambiar la interfaz gráfica de su aplicación Web en una API Web - Además, el diseño de la API es a menudo impulsado por la idea de que todo lo que se puede hacer en la interfaz gráfica también debería hacerse a través del API.
La combinación de las dos tareas es una buena manera de conseguir una mejor interfaz web para ambos, los seres humanos y las aplicaciones.
En resumen: Ofrezca diferentes formatos de los recursos para diferentes necesidades.
Comunicar sin un estado
El último principio me gustaría abordar es la comunicación sin estado. En primer lugar, es importante señalar que, aunque REST incluiya la idea de "no mantener", eso no significa que la aplicación que exponga sus funcionalidades no pueda tener estado -de hecho, esto haría que el enfoque sea inútil en la mayoría de los escenarios. REST exige que el estado sea transformado en estado del recurso y sea mantenido en el cliente. En otras palabras, un servidor no debería guardar el estado de la comunicación de cualquiera de los clientes que se comunican con él más allá de una petición única. La razón más obvia de esto es la escalabilidad - el número de clientes que pueden interactuar con el servidor se vería significativamente afectada si fuera necesario mantener el estado del cliente. (Tenga en cuenta que por lo general requiere un poco de re-diseño - no se puede mantener simplemente una URI con algunas sesiones con el estado y llamar a eso RESTful.)
Pero hay otros aspectos que podrían ser mucho más importantes: Las restricciones de "no mantener" aislar al cliente de cambios en el servidor, por lo tanto, dos solicitudes consecutivas no dependen de la comunicación con el mismo servidor. Un cliente podría recibir un documento que contiene los enlaces al servidor y, a continuación, hacer algún procesamiento, y el servidor podría ser apagado, y el disco rígido podría ser sacado o sustituido, y el software podría ser actualizado y reiniciado - y si el cliente accede a los links que recibió del servidor, no tendría que percibirlo.
REST en Teoría
Tengo una confesión que hacer: ¿Lo qué he explicado no es realmente REST, y quzás fue simplificar demasiado. Pero quería empezar las cosas de una manera un poco diferente de lo habitual, por lo que no hablé del escenario formal y de la historia de REST en el inicio. Permítanme tratar de resolver este problema, con algo breve.
Antes que todo, evité tener mucho cuidado en separar REST de HTTP en sí del uso de HTTP de forma RESTful. Para entender la relación entre estos dos diferentes aspectos, tenemos que echar un vistazo a la historia de REST.
El término RESTo fue definido por Roy T. Fielding en su tesis doctoral (es posible que desee ver este enlace - es muy legible, por lo menos para una tesis). Roy fue uno de los principales desarrolladores de muchos de los principales protocolos Web, incluyendo HTTP, y URI, y él formalizó muchas de las ideas detrás de este documento. (la disertación es considerada "la Biblia de REST", y con razón - ya que el autor inventó el tema, entonces por definición, todo lo que escribe debe ser considerado imperativo.) En esta disertación, Roy define en primer lugar una metodología para hablar de estilos arquitectónicos - de alto nivel, patrones de abstracción que expresan las principales ideas detrás de un enfoque arquitectónico. Cada estilo arquitectónico con un conjunto de normas que lo define.
Ejemplos de estilos arquitectónicos incluyen "estilo nulo "(que no tiene reglas), pipe (tubería) y filter (filtro), cliente / servidor, objetos distrubuídos - adivinen qué? - REST.
Si todo esto suena un poco abstracto para usted, está en lo cierto -REST en sí mismo es un estilo de alto nivel que puede ser implementado utilizando diferentes tecnologías, e instanciado utilizando diferentes valores para propiedades abstractas. Por ejemplo, REST incluye conceptos de recursos y una interfaz uniforme -es decir, la idea de que todo recurso debería responder a los mismos métodos. Pero REST no dice qué métodos deben ser, ni cuantos deben ser.
Una "encarnación" del estilo REST es el HTTP (y un conjunto de conjuntos relacionados de padrones como las URIs), o de forma un poco más abstracta: la arquitectura de la Web en sí. Para continuar con el ejemplo anterior, HTTP "instancia" una interface uniforme de REST con una interfaz especial, que consiste en verbos HTTP. Como Fielding definió, el estilo REST despues la Web - o al menos la mayor parte de ella - ya estaba lista, alguien podría argumentar cuando fueron 100% relacionados. Pero en cualquier caso, la Web, HTTP y URI son las únicas mayores, ciertamente las únicas instancias relevantes del estilo REST como un todo. Y, como Roy Fielding es el autor de la tesis de REST, tal como ha sido una fuerte influencia en el diseño de la arquitectura de la Web, esto no debería sorprender.
Por último, he utilizado el término "HTTP RESTful" de vez en cuando, por una sencilla razón: Muchas aplicaciones que utilizan HTTP que no se ajusta a los principios REST -y con cierta justificación, uno podría decir que usan HTTP sin seguir los principios REST y lo que es lo mismo que abusar de HTTP. Es claro que eso suena un poco exagerado -y, a menudo, de hecho, hay razones por las cuales puede violar una norma de REST, simplemente porque toda regla induce algunas ventajas y desventajas que pueden no ser aceptables en una situación en particular. Sin embargo, a menudo, las reglas de REST se violan debido a una simple falta de comprensión de sus beneficios. Para proporcionar un ejemplo particularmente perverso: el uso de HTTP GET para invocar operaciones tales como eliminar un objeto viola una regla de seguridad de REST y el buen sentido común (el cliente HTTP no puede ser considerado responsable, lo que probablemente no es lo que el desarrollador del servidor quería hacer). Hay muchos otros abusos notables.
Resumen
En este artículo, he intentado ofrecer una rápida introducción a los conceptos detrás de REST, la arquitectura de la Web. Un enfoque HTTP RESTful para exponer funcionalidad de una manera diferente de RPC, objetos distribuidos y Web Services, eso lleva algún tiempo para la comprensión y el real entendimiento de la diferencia. Ser consciente de que los principios de REST traen beneficios cuando está construyendo aplicaciones que sólo expone la interfaz gráfica en la Web o si quiere transformar la API de su aplicación en un buen ciudadano de la Web.
Stefan Tilkov es el editor líder de la comunidad SOA en InfoQ, co-fundador y consultor principal y lidera.
